D2C2: Automatisierte Berichterstattung mit Text und Visualisierung — zwischen Potenzial und Unsicherheit
Profitiert der Journalismus davon, wenn künftig Algorithmen aus Wahlprognosen und -ergebnissen eigene Artikel erzeugen? Das wollte das Projekt Data Driven Campaign Coverage (D2C2) herausfinden.
Sport, Wirtschaft, Wahlen: Berichterstattung über diese Themen beinhaltet auch immer Berichterstattung über Zahlen — Sportergebnisse, Quartalsabschlüsse, Prognosen und Wahlergebnisse.
Seit 2004 erstellt PollyVote Prognosen darüber, wie Wahlen ausgehen — etwa die US-Wahl 2008 oder die Bundestagswahl 2013. Kommunikationswissenschaftler Andreas Graefe ist seit 2007 an dem Projekt beteiligt, er untersucht, wie gut sich Wahlausgänge vorhersagen lassen.
"Wir haben gemerkt, dass wir mit PollyVote eigentlich ein journalistisches Produkt haben, aber nicht die Kapazitäten, es auf diese Anwendung hin zu entwickeln und Content daraus zu generieren. Da lag es auf der Hand, im Rahmen dieses Forschungsprojektes zu analysieren, wie wir uns die Vorteile der Automatisierung zunutze machen können", sagt Graefe, der an der Macromedia Hochschule und der Columbia Universität forscht.
Genau darum geht es beim Projekt "Data Driven Campagne Coverage" (D2C2): Lassen sich automatisiert journalistische Berichte und Visualisierungen erstellen, die für Mediennutzer verständlich sind? Das Projekt besteht also aus zwei Komponenten: einem Modul, das auf Basis von PollyVotes Prognose- und Wahlergebnissen automatisiert Berichte erstellt. Und einem zweiten Modul, das auf Basis der Zahlen automatisiert Visualisierungen generiert, die von Journalisten zur Berichterstattung verwendet werden könnten.
Die Aufgabe des Teams um Datenjournalist Mirko Lorenz von der Deutschen Welle war vor allem in der Entwicklungsphase die Qualitätssicherung, um Verständlichkeit und Lesbarkeit zu gewährleisten. In einem späteren Regelbetrieb sollen Journalisten und Redakteuren von der Arbeit der Algorithmen profitieren können.
"Das Training von solchen Robot-Journalism-Datenbanken könnte eine zukünftige Rolle von Journalisten sein. Und das muss gar nicht mal schlecht sein, denn theoretisch entlasten die Algorithmen dann die Redaktion von eher lästigen Routineberichten. Durch Datenbankpflege trotzdem weiterhin für eine sehr hohe Qualität zu sorgen — ob das jetzt regionale Fußballspiele oder regionale Wahlergebnisse sind — , gehört auch weiterhin zur journalistischen Sorgfaltspflicht", sagt Lorenz. Dass diese automatisch generierten Texte am Ende genauso gut sein können, wie die von Menschen geschriebenen, da ist er sich nach diesem Projekt sicher.
Automatisierte Berichterstattung hat Grenzen — noch
Das bestätigt auch die Erfahrung anderer Redaktionen: Seit 2014 setzt die Nachrichtenagentur Associated Press (AP) auf Algorithmen bei der Berichterstattung über Konzerne: Die Anzahl an Firmen, die sie etwa mit Artikeln zu Quartalszahlen abdecken, ist von 400 auf 4.000 angestiegen. Während gerade am Anfang Redakteure noch mehr kontrolliert und nachgebessert haben, läuft der Prozess inzwischen vollautomatisch; für rund 100 Unternehmen monitoren Reporter, ob ein detaillierter Bericht oder eine zusätzliche Geschichte erforderlich ist. So ermöglicht der Algorithmus den Reportern, sich auf das Wesentliche zu konzentrieren und mehr Zeit auf die Geschichten hinter den Zahlen zu verwenden.
Im Rahmen des Projektes D2C2 wurden rund 22.000 deutsche und englische Berichte zur US-Wahl 2016 erzeugt. "Es ist viel Potenzial da, allerdings merkt man auch schnell, wo die Grenzen der Text-Automatisierung liegen. Man muss für jede mögliche Datenkonstellation eine Regel definieren, in welche Textaussage sie münden soll", erklärt Graefe. Der Algorithmus prüft die eingehenden Daten und sucht basierend darauf in seiner Datenbank nach einer Referenz, die Daten desselben Musters erhält. Zusätzlich zu jedem Daten-Muster ist ein Textfragment hinterlegt, dass die Zahlen in einem ausformulierten Satz kontextualisiert. So baut der Algorithmus satzweise basierend auf der Datenlage einen Text auf.
"Aber viele Daten — gerade bei dem Thema Wahlen — kann man nicht kontext-unabhängig betrachten", so Graefe weiter. Ein Beispiel sei etwa der Abstand der Kandidaten in Umfragen. "Auf den ersten Blick sieht es so aus, als sei das relativ einfach in Regeln umzusetzen: Alles bis vier Punkte ist ein 'kleiner Abstand', alles bis zehn Punkte ist ein 'großer Abstand' und alles darüber ein 'sehr großer Abstand'. Das kann man natürlich in einer Formel umsetzen. Das Problem ist aber die Kontextabhängigkeit. Kurz vor der Wahl war ein Vier-Punkte-Vorsprung für Hillary Clinton normal. Aber vier Punkte Vorsprung für Trump wären eine außergewöhnliche Meldung gewesen. Und diesen Kontext mit einem Algorithmus abzubilden, ist sehr schwierig."
Graefes Team hat trotzdem versucht, dieses Problem zu lösen. In Zeitungsartikeln wurde ausgewertet, wann welche Begriffe verwendet wurden. Zusätzlich wurden Journalisten befragt, wann sie welche Adjektive nutzen, um die Abstände der Kandidaten in der Wählergunst zu beschreiben. Alle diese Informationen flossen ein in den Algorithmus, der die Texte zusammenbaut. Dieser Projektteil wurde in Kooperation mit der Softwarefirma AX Semantics umgesetzt, die sich auf das Feld der automatisierten Content-Erstellung spezialisiert hat.
Lorenz, der als Innovationsmanager bei der Deutschen Welle mit vielen externen Partnern zusammenarbeitet, war überrascht, wie offen Wissenschaftler und Informatiker für den Input der Journalisten waren: "Diese übliche Kolportage über Informatiker 'Jetzt wird der Text automatisch generiert, dann brauche ich ja keinen einzigen Journalisten mehr', das hat sich in der Realität unserer Arbeitsgruppe nicht abgebildet. Wir waren begeistert, wie sehr das Team von AX Semantics Unterstützung von uns Journalisten eingefordert hat. Und auch überrascht, was dazu an umfassendem Wissen über Text, Statistik und Programmier-Kenntnissen erwartet wurde. Für uns war es völlig neu, dass Journalisten so intensiv an wissenschaftlichen Modellen mitarbeiten sollten.“
Visualisierungen aufbereitet für ein Medienpublikum statt für Wissenschaftler
Auch bei dem zweiten Projektmodul — dem Erstellen von journalistisch nutzbaren Visualisierungen auf Basis von PollyVote-Daten — floss die Erfahrung der Journalisten um Lorenz ein: Immer wieder hinterfragten sie Aspekte, die die Wissenschaftler als selbstverständlich angenommen hatten.
"Für mich war das Lehrreiche aus dem Projekt, dass uns die Kollegen der Deutschen Welle immer wieder ein bisschen eingebremst haben. Sie haben immer wieder gesagt: Das ist für den Durchschnittsuser viel zu komplex. Wir mussten eine Balance finden zwischen dem, was wir als Wissenschaftler vermitteln wollen und dem, was einer breiten Öffentlichkeit zumutbar ist. Auf der charts.pollyvote.comSeite sieht man aus meiner Sicht sehr schön das Ergebnis der Reduktion von Komplexität", resümiert Graefe.
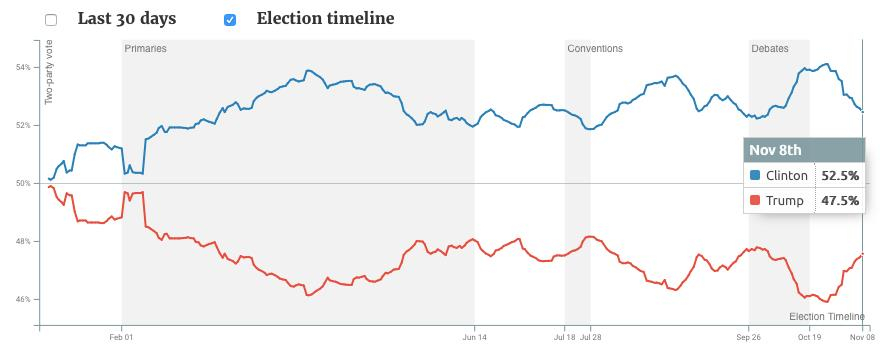
Ein Beispiel ist die Fieberkurve, die seit Anfang 2016 — täglich aktualisiert — das damals prognostizierte Ergebnis für die US-Präsidentschaftswahl anzeigt: Zu Beginn liegen die Umfrage-Werte von Trump (rote Linie) und Clinton (blaue Linie) noch relativ nah beieinander, entfernen sich aber mit der Zeit immer mehr. Die gesamte Zeit führt Clinton — meist mit großem Vorsprung. "In der Ursprungsversion der Grafik gab es nur eine Linie; für die Wissenschaftler war automatisch klar, dass die Kurve für den anderen Kandidat das Spiegelbild der abgebildeten war. Einem normalen Nutzer ist sowas aber nicht klar, deswegen haben wir hier die zweite Linie hinzugefügt und auch die Farben der jeweiligen Partei verwendet", erklärt Lorenz die Anpassung der Visualisierung.

Das Projekt D2C2 bewegt sich dabei im Kontext von amerikanischen Medien: Zu Olympia 2016 hatte die Washington Post Heliograf entwickelt, das ebenfalls bei der Berichterstattung zur Wahl eingesetzt wurde: In beiden Fällen erstellte das Tool automatisiert Text zu den Ergebnissen und twitterte diese auch noch.
Die Nachrichtenagentur Reuters vermeldete im September 2016 eine Kooperation mit dem Unternehmen Graphiq, um generell die Berichterstattung mit Visualisierungen zu automatisieren.
D2C2 geht noch einen Schritt weiter und verbindet beides, bietet automatisierten Text und Visualisierung in einem Paket. In einem denkbaren Business-Modell sollen Redaktionen diesen Service einkaufen können.
Wissenschaftler, Journalisten und Nutzer unsicher im Umgang mit Unsicherheit
D2C2 war insofern erfolgreich, als dass die automatische Generierung von Text und Visualisierung funktioniert. Ein Knackpunkt ist jedoch die Unsicherheit, mit der die Datenbasis behaftet ist, auf der das Produkt aufbaut. Denn Pollyvote sagte — wie viele andere Vorhersage-Modelle auch — einen Sieg für Clinton vorher.
Gerade im Kontext der US-Wahl 2016 prangerte der Datenjournalist Nate Silver, der die Seite FiveThirtyEight gegründet hat, an, dass viele Journalisten entweder selbst nicht verstanden haben, mit welcher Unsicherheit Prognosen behaftet sind, oder es nicht entsprechend kommuniziert haben.
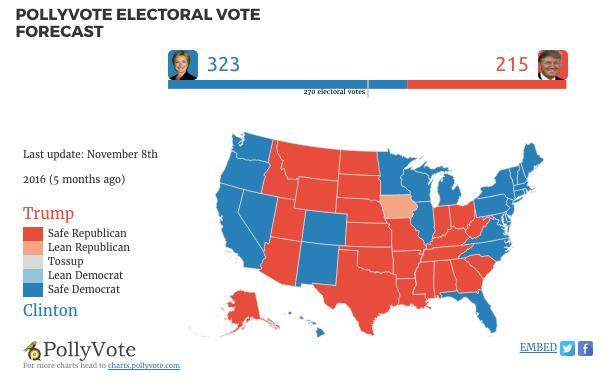
Auch auf der PollyVote-Seite gibt es ein Beispiel dafür. Einen Tag vor der Wahl veröffentlicht Graefe einen Blogpost mit dem Titel "Final Pollyvote Forecast: Clinton will win". Darin enthalten ist untenstehende Karte, die einzelnen US-Staaten sind in Blau- und Rot-Tönen eingefärbt, die in der Legende unter anderem "Safe Democrat", "Safe Republican" zugeordnet werden. Kommunizierte Unsicherheit? Keine Spur.
"Wir haben uns für diese Codierung entschieden, um die Übereinstimmung der verschiedenen Prognosemethoden zu kommunizieren. Für einen Staat, der als 'sicher’ für eine Partei eingestuft wurde, haben alle verfügbaren Methoden beispielsweise den gleichen Gewinner vorhergesagt ", erklärt Graefe. "Letztendlich war das eine pragmatische Entscheidung – aber im Nachhinein keine gute.“
Graefe sagt, dass es auch auf wissenschaftlicher Seite noch Verbesserungspotenzial gibt: "Wie man verschiedene Prognosemodelle kombinieren kann, ist eines der am besten untersuchten Felder im Bereich der Vorhersageforschung. Man weiß, es funktioniert verlässlich. Was man nicht weiß, ist, wie man am besten Unsicherheit, mit der Prognosen behaftet sind, direkt mit in die kombinierte Prognose integriert."
Und selbst wenn das gelänge: Leider können die meisten Rezipienten kommunizierte Unsicherheit trotzdem nicht richtig interpretieren, wie verschiedene Studien zeigen. Sie nehmen Prognosen für bare Münze.
Was bleibt und was sich ändern muss
Einen Ansatzpunkt, die Datengrundlage zu verbessern, um die Unsicherheit weiter zu minimieren, sieht Graefe in den Expertenbefragungen, die künftig in die Prognosen mit einfließen sollen: "Wir überlegen, Experten künftig zu bitten, sich bewusst Szenarien auszudenken, welche gegen das Eintreten der eigenen Prognose sprechen, und sie dann zum Abgeben einer zweiten Prognose aufzufordern. Forschungsergebnisse zeigen, dass dieser Ansatz hilft, Wunschdenken und Confirmation Bias zu reduzieren und damit die Prognosegenauigkeit zu verbessern."
Graefe blickt durchaus optimistisch in die Zukunft von Wahlprognosen. "Die Aufmerksamkeit für das Thema Prognosen war noch nie so hoch wie jetzt, was für unsere Arbeit erst einmal positiv ist. In der Vergangenheit war es immer so, dass wir mit PollyVote richtig lagen, was im Nachhinein niemanden interessiert hat. Jetzt, wo wir mit unserer Prognose für die US-Wahl daneben lagen, hat das Telefon zwei Tage lang nicht aufgehört zu klingeln", sagt Graefe. "Wenn das Vertrauen in Prognosen durch dieses Ergebnis geschwächt ist, dann ist auch das etwas Positives. Was wir definitiv besser machen können und müssen, ist die Kommunikation von Unsicherheit."
Für Wahl-Prognosen im journalistischen Kontext ist Graefes Partner Lorenz skeptischer. Zumindest vorerst: "Große Häuser wie die Deutsche Welle, oder auch andere öffentliche Sender, sind keine Startups. Glaubwürdigkeit hat eine zentrale Bedeutung. Irgendwann werden Datenmodelle präziser die Zukunft vorhersagen können. Aber unser derzeitiges Fazit ist: Im Moment braucht man davon eigentlich nicht anzufangen, für uns sind Vorhersagemodelle journalistisch nicht wirklich nutzbar. Zum einen wegen des Misserfolgs bei dieser besonderen US-Wahl. Dass die Exaktheit der Vorhersage von sehr vielen Faktoren abhängt war uns zwar klar, doch gesucht wird natürlich nach noch besseren Methoden."
Aufgeben würde Lorenz das Thema dennoch nicht: "Wir sind sehr zufrieden mit dem Projekt, weil wir die Chance hatten an einem der komplexen Randbereiche — journalistische, datengetriebene Berichterstattung und statistische Visualisierung — aktiv zu arbeiten, an einem wichtigen Weltereignis und nicht nur irgendwo im stillen Kämmerlein. Solche Chancen hat man selten, deswegen war das Projekt wichtig. Es gehört aber nun mal zum Wesen der Innovation dazu, dass man es möglicherweise drei, vier, fünf Mal probieren muss und es nicht gleich beim ersten Mal funktioniert."
Gianna Grün
Projektinformationen D2C2
Hauptantragsteller
Andreas Graefe, Macromedia Hochschule, München
Mirko Lorenz, Datenjournalist, Deutsche Welle
Publikationen
Peer-reviewed papers
1. Graefe, A., Armstrong, J. S., Jones, R. J. J. & Cuzán, A. G. (2017). The 2016 PollyVote popular vote forecast: A preliminary analysis. PS: Political Science & Politics, 50(2), forthcoming.
2. Graefe, A. (2017). Prediction market performance in the 2016 U.S. presidential election. Foresight – The International Journal of Applied Forecasting, forthcoming.
3. Graefe, A., Jones, R. J. J., Armstrong, J. S. & Cuzán, A. G. (2016). The PollyVote forecast for the 2016 American Presidential Election. PS: Political Science & Politics, 49(4), 687-690.
4. Graefe, A., Haim, M., Haarmann, B. & Brosius, H.-B. (2016). Readers‘ perception of computerwritten news: Credibility, expertise, and readability Journalism (Online first).
Book chapters
1. Graefe, A., Armstrong, J. S., Jones, R. J. J. & Cuzán, A. G. (2017). Assessing the 2016 U.S. presidential election popular vote forecasts. In A. Cavari, R. Powell & K. Mayer (Eds.), The 2016 Presidential Election: The causes and consequences of an electoral earthquake. Lanham, MD: Lexington Books.
2. Haim, M. & Graefe, A. (2017). Automatisierter Journalismus: Anwendungsbereiche, Formenund Qualität. In C. Nuernbergk & C. Neuberger (Eds.), Journalismus im Internet: Profession – Partizipation – Technisierung (in press).
Other writings
1. Graefe, Andreas (2016). Don’t trust a single forecast. The consensus all year has been that Clinton will win. Washington Post, Monkey Cage, September 22, 2016.
2. Graefe, Andreas (2016). How to improve polling? Ask voters who will win. The Hill, September 7, 2016.
3. Graefe, Andreas (2016). Get better predictions by combining diverse forecasts. The Conversation, August 23, 2016.
4. Graefe, Andreas (2016). Political scientists predict Clinton will win 347 electoral votes in November. United States Politics and Policy Blog, London School of Economics, August 22, 2016.
5. Graefe, Andreas & Mario Haim (2016). Člověk nebo algoritmy? Čí články čtenáři upřednostňují? European Journalism Observatory, May 25, 2016.
6. Graefe, Andreas & Mario Haim (2016). Human Or Computer? Whose Stories Do Readers Prefer? European Journalism Observatory, May 17, 2016.
7. Graefe, Andreas & Mario Haim (2016). Wenn Algorithmen Journalismus machen. European Journalism Observatory, May 17, 2016.
8. Graefe, Andreas & Mario Haim (2016). Quando a scrivere è un algoritmo. European Journalism Observatory, May 11, 2016.